PipeHub: ETL on Github Actions
This is an explanation and rationale for PipeHub, which will be an open-source package for running ETL and reverse ETL pipelines on GitHub Actions.
The landscape
ETL tools are really expensive and have opaque pricing.
If you go to Fivetran's pricing page, you won't see a single number that describes their pricing. Instead, they link you to a page on their legal site with a consumption table.
Good luck trying to figure out how much it will cost to set up a few different syncs!
This is true for other software in this space as well.
All of these tools have the inevitable "Contact Sales" or "Get a demo" button. Nobody wants to talk to a salesperson from an ETL company.
Open source isn't a panacea
Even if you wanted to run workflows on your own infrastructure to save costs, you're still in a difficult position.
Airbyte is another product in this space that has an open source and cloud offering.
Here's a diagram from the Airbyte Self-managed Enterprise guide on how to deploy Airbyte in AWS:
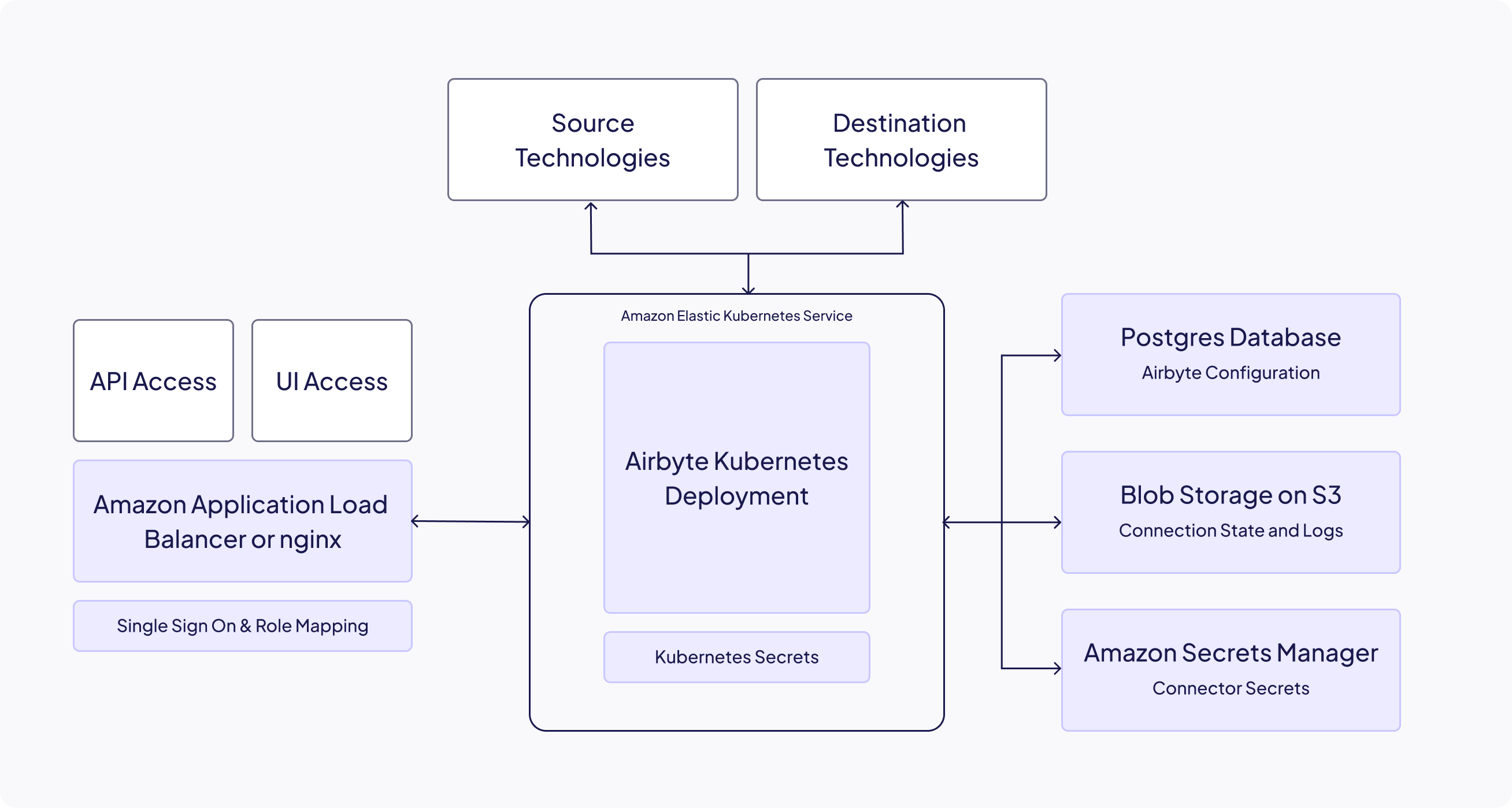
Then, it goes on to describe how you need:
- an EKS cluster in 2 or more availability zones
- a minimum of 6 nodes
- an ingress ALB
- an s3 bucket
- a dedicated RDS database (with read replica)
- an external secrets manager
Just to get started.
Most customers of ETL products aren't able or willing to do this; they pony up for the cloud version.
Why is ETL hard?
ETL platforms have to:
- Write hundreds of connectors
- Maintain hundreds of connectors
- Build a workflow scheduling and management engine
- Allow some form of version management
- Allow SSO and role-based access control support
- Alert / notify customers when things go wrong
- Orchestrate tons of running containers, provision new machines
- Allow customers to monitor and read logs
- Support pricing / tracking software
- Secrets management
These things are all hard and require years of engineering investment.
GitHub?
Enter an unlikely hero: GitHub Actions.
Workflow scheduling and management
You can schedule workflows up to every five minutes or trigger them with webhooks.
Version management
It's GitHub. You can manage your connections as code.
Here's an example of how powerful GitHub-managed connections can be. You can create a PR with a new connection workflow and run the workflow with test data. That's really hard to do with existing tooling! And you get that out of the box.
Another example: users who notice a bug and know how to fix it can fork the action code, fix the bugs, and run the action with their fork until the fix is upstreamed.
Allow SSO and role-based access control
You can assign certain users to be able to view or have merge rights on repositories. GitHub already has these features.
Alert / notify on failures in workflows
GitHub can also already alert or notify you when your action fails!
Orchestrate containers on VMs
GitHub Actions already has tons of options for VMs. These include runners with 2TB SSDs and 256GB of RAM. This is enough for the vast majority of ETL workloads using something like DuckDB.
They are on the expensive side, but this is nothing compared to the pricing you're getting from ETL providers.
If you want to minimize cost or run into limits with the GitHub Action runners you can host your own, which is a lot easier than self-hosting something like AirByte.
Allow customers to monitor jobs and see logs
GitHub Actions allows you to see logs and monitor the jobs.
Support pricing
GitHub has pricing breakdowns as well! You can easily see and control how much you're spending and schedule fewer jobs.
Secrets management
GitHub Actions also supports storing and managing secrets and environment variables already.
PipeHub
Bolded are the features we need that GitHub Actions already has:
- Write hundreds of connectors
- Maintain hundreds of connectors
- Build a workflow scheduling and management engine
- Allow some form of version management
- Allow SSO and role-based access control support
- Alert / notify customers when things go wrong
- Orchestrate tons of running containers, provision new machines
- Allow customers to monitor and read logs
- Support pricing / tracking software
- Secrets management
GitHub Actions is too perfect for ETL. All you need is the connector code.
This is the vision of PipeHub: run open source connectors inside custom GitHub Actions.
All of your ETL pipelines are version controlled YAML in .github/workflows. No provisioning infrastructure. No surprise bills. No awkward sales negotiation.
Risks
GitHub platform risk
If this gets too annoying for GitHub (platforms banning their action IPs, customers using too many runners, etc.), they might start banning usage of the action.
My bet is the incentives are aligned here: providers want to their users to get value from their data and GitHub (based on their pricing) makes a solid margin on GitHub Action runners.
This is certainly the biggest risk.
Nobody cares
It's possible that users of Fivetran and similar tools aren't frustrated enough with pricing. I doubt this is the case: there are tons of complaints on the r/dataengineering subreddit about Fivetran and related tools.
The procurement process for tools like Fivetran is also really tough. You have to spend a ton of time in meetings begging for budget only to get denied.
Lots of teams already have GitHub subscriptions, and can spin up a new repo with a GitHub Action. Many workflows will be less than a dollar (or essentially free).
Connector Atrophy
One risk is that the connector code breaks over time and doesn't get fixed by the open source community.
- It's open source so they can report the issue (and fix it if they're savvy enough)
- This is a problem with proprietary ETL solutions as well. They often break and the ETL providers have trouble keeping up.
We'll probably need integration tests with real customer data to make sure we know about issues ahead of time. That will be tough and take a lot of resources.
Burnout
If PipeHub is successful, there will be hundreds of connectors with thousands of users relying on them for mission critical workloads. That's a huge burden to take on for any open source project, especially since certain issues (outages in connected systems, breaking API or schema changes without warning) are often out of our control.
There are a couple tailwinds that help this:
- It's open source for a technical audience. They can pitch in since they'll be getting immense value.
- LLMs make writing integrations way way way easier. You can get to a first draft faster. LLMs also make writing tests faster, which will help ship with confidence.
Ultimately, open source is really hard and having a path to a sustainable business will be really key.